Önbellek algoritması
Önbellek algoritması, bir önbelleği veya veri grubunu yönetmek için kullanılan bir algoritmadır. Önbellek dolduğunda, hangi öğenin önbellekten silinmesi gerektiğine karar verir. İsabet oranı kelimesi, bir isteğin önbellekten ne sıklıkla sunulabi…
Önbellek algoritması, bir önbelleği veya veri grubunu yönetmek için kullanılan bir algoritmadır. Önbellek dolduğunda, hangi öğenin önbellekten silinmesi gerektiğine karar verir. İsabet oranı kelimesi, bir isteğin önbellekten ne sıklıkla sunulabileceğini açıklar. Gecikme terimi, önbelleğe alınan bir öğenin ne kadar süreyle elde edilebileceğini açıklar. Önbellek algoritmaları, isabet oranı ve gecikme arasında bir değiş tokuştur.
- En verimli önbellekleme algoritması, gelecekte en uzun süre ihtiyaç duyulmayacak bilgileri her zaman atmak olacaktır. Bu optimal sonuç, Belady'nin optimal algoritması veya basiret algoritması olarak adlandırılır. Bilgiye ne kadar gelecekte ihtiyaç duyulacağını tahmin etmek genellikle imkansız olduğundan, bu genellikle pratikte uygulanabilir değildir. Pratik minimum ancak deneylerden sonra hesaplanabilir ve gerçekte seçilen önbellek algoritmasının etkinliği optimum minimum ile karşılaştırılabilir.
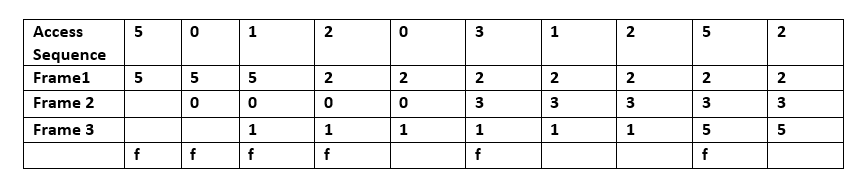
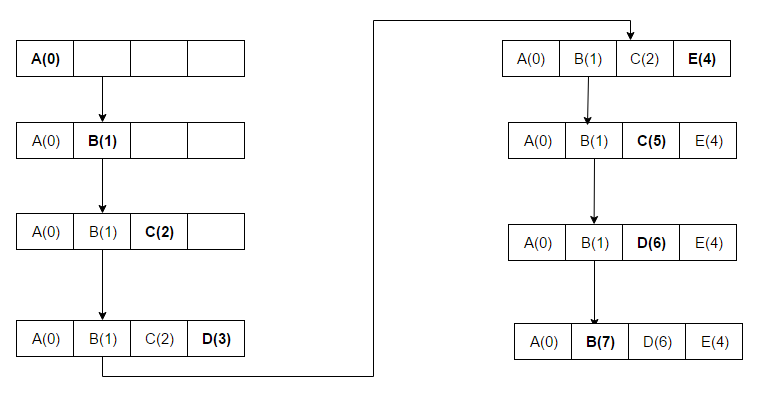
- En Son Kullanılan (LRU): en son kullanılan öğeleri önce siler. Bu algoritma, neyin ne zaman kullanıldığını takip etmeyi gerektirir. Algoritmanın her zaman en son kullanılan öğeyi attığından emin olmak isteniyorsa bu pahalı bir işlemdir. Bu tekniğin genel uygulamaları, önbellek satırları için "yaş bitleri" tutmayı ve yaş bitlerine dayalı olarak "En Son Kullanılan" önbellek satırını izlemeyi gerektirir. Böyle bir uygulamada, bir önbellek satırı her kullanıldığında, diğer tüm önbellek satırlarının yaşı değişir. LRU aslında üyeleri olan bir önbellekleme algoritması ailesidir: Theodore Johnson ve Dennis Shasha tarafından geliştirilen 2Q ve Pat O'Neil, Betty O'Neil ve Gerhard Weikum tarafından geliştirilen LRU/K.
- En Son Kullanılan (MRU): Bu algoritma ilk olarak en son kullanılan öğeleri siler. Bu önbellekleme mekanizması genellikle veritabanı bellek önbellekleri için kullanılır.
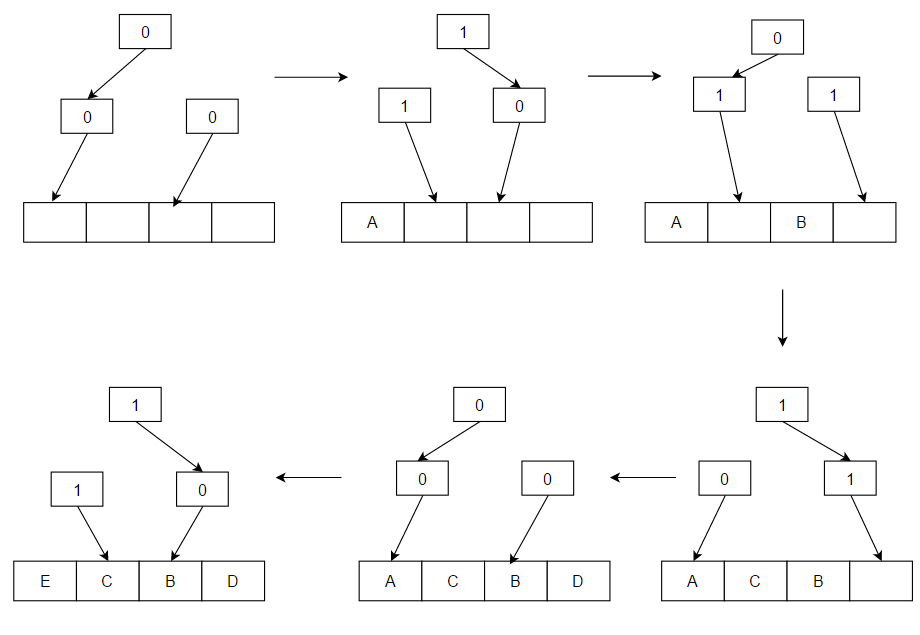
- Pseudo-LRU (PLRU): LRU'nun uygulanmasının çok zor olduğu bazı durumlar vardır. Bu gibi durumlarda, çoğu durumda en son kullanılan öğelerden birinin silindiğini bilmek yeterli olabilir. PLRU algoritması burada kullanılabilir, çünkü çalışmak için önbellek öğesi başına yalnızca bir bit gerekir.
- 2 yönlü set ilişkisel: PLRU'nun bile çok yavaş olduğu yüksek hızlı CPU önbellekleri için. Yeni bir öğenin adresi, önbellekte gitmesine izin verilen iki olası konumdan birini hesaplamak için kullanılır. İkisinden LRU olanı atılır. Bu, hangisinin en son kullanıldığını belirtmek için her önbellek satırı çifti için bir bit gerektirir.
- Doğrudan eşlemeli önbellek: 2 yönlü set ilişkisel önbelleklerin bile çok yavaş olduğu en yüksek hızlı CPU önbellekleri için. Yeni öğenin adresi, önbellekte gitmesine izin verilen bir konumu hesaplamak için kullanılır. Daha önce orada ne varsa atılır.
- En Az Sıklıkta Kullanılan (LFU): LFU, bir öğeye ne sıklıkta ihtiyaç duyulduğunu sayar. En az sıklıkta kullanılanlar ilk önce atılır.
- Uyarlanabilir Değiştirme Önbelleği (ARC): Birleşik sonucu iyileştirmek için LRU ve LFU arasında sürekli denge kurar.
- Çoklu Kuyruk (MQ) önbellekleme algoritması: (Y. Zhou J.F. Philbin ve Kai Li tarafından).
Dikkate alınması gereken diğer şeyler:
- Farklı maliyetli öğeler: elde edilmesi pahalı olan öğeleri, örneğin elde edilmesi uzun zaman alan öğeleri saklayın.
- Öğeler daha fazla önbellek kaplıyor: Öğeler farklı boyutlara sahipse, önbellek birkaç küçük öğeyi depolamak için büyük bir öğeyi atmak isteyebilir.
- Zamanla süresi dolan ürünler: Bazı önbellekler süresi dolan bilgileri saklar (örneğin haber önbelleği, DNS önbelleği veya web tarayıcısı önbelleği). Bilgisayar, süresi dolduğu için öğeleri atabilir. Önbelleğin boyutuna bağlı olarak öğeleri atmak için başka bir önbellekleme algoritması gerekmeyebilir.
Önbellek tutarlılığını korumak için çeşitli algoritmalar da mevcuttur. Bu yalnızca aynı veri için birden fazla bağımsız önbelleğin kullanıldığı durumlar için geçerlidir (örneğin tek bir paylaşılan veri dosyasını güncelleyen birden fazla veritabanı sunucusu).
Görsel galerisi
7 Görseller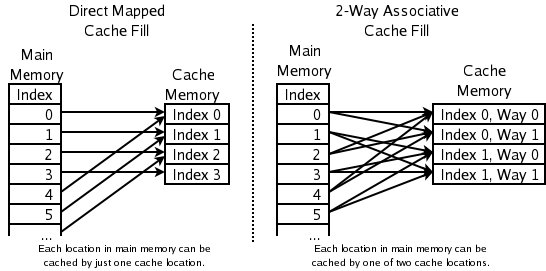




Sorular ve yanıtlar
S: Önbellek Algoritması nedir?
C: Önbellek algoritması, bir önbelleği veya veri grubunu yönetmek için kullanılan bir algoritmadır. Önbellek dolduğunda hangi öğenin önbellekten silinmesi gerektiğine karar verir.
S: İsabet oranı nedir?
C: İsabet oranı, bir isteğin önbellekten ne sıklıkla sunulabileceğini açıklar.
S: Gecikme süresi neyi tanımlar?
C: Gecikme, önbelleğe alınan bir öğenin ne kadar süreyle elde edilebileceğini açıklar.
S: Belady'nin optimal algoritması nedir?
C: Durugörü algoritması olarak da bilinen Belady'nin optimal algoritması, gelecekte en uzun süre ihtiyaç duyulmayacak bilgileri her zaman atan verimli bir önbellekleme algoritmasıdır. Bu sonuç genellikle pratikte uygulanamaz çünkü gelecekte neye ihtiyaç duyulacağının tahmin edilmesini gerektirir.
S: En Son Kullanılan (LRU) nasıl çalışır?
C: LRU ilk olarak en son kullanılan öğeleri siler ve her bir önbellek satırı için "yaş bitleri" kullanarak ve yaş bitlerine göre hangisinin en son kullanıldığını izleyerek neyin ne zaman kullanıldığını takip etmeyi gerektirir. Bir önbellek satırı her kullanıldığında, diğer tüm önbellek satırlarının yaşları buna göre değiştirilir.
S: En Son Kullanılan (MRU) nasıl çalışır?
C: MRU ilk olarak en son kullanılan öğeleri siler ve bu önbellekleme mekanizması genellikle veritabanı bellek önbellekleri için kullanılır.
S: Önbellek tutarlılığını korumak için başka hangi algoritmalar vardır?
C: Tek bir paylaşılan veri dosyasını güncelleyen birden fazla veritabanı sunucusu gibi paylaşılan veriler için birden fazla bağımsız önbellek kullanıldığında önbellek tutarlılığını korumak için çeşitli algoritmalar mevcuttur.
İlgili makaleler
Yazar
AlegsaOnline.com Önbellek algoritması Leandro Alegsa
URL: https://tr.alegsaonline.com/art/15882
Kaynaklar
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org