Zipf yasası
Zipf yasası, matematiksel istatistikler kullanılarak formüle edilmiş ampirik bir yasadır ve adını ilk kez öneren dilbilimci George Kingsley Zipf'ten almıştır. Zipf yasası, kullanılan kelimelerin büyük bir örneği verildiğinde, herhangi bir kelime…
Zipf yasası, matematiksel istatistikler kullanılarak formüle edilmiş ampirik bir yasadır ve adını ilk kez öneren dilbilimci George Kingsley Zipf'ten almıştır.
Zipf yasası, kullanılan kelimelerin büyük bir örneği verildiğinde, herhangi bir kelimenin sıklığının, sıklık tablosundaki sıralamasıyla ters orantılı olduğunu belirtir. Yani n numaralı kelime 1/n ile orantılı bir sıklığa sahiptir.
Böylece en sık kullanılan kelime, ikinci en sık kullanılan kelimenin yaklaşık iki katı, üçüncü en sık kullanılan kelimenin üç katı, vb. sıklıkta ortaya çıkacaktır. Örneğin, İngilizce dilindeki bir kelime örneğinde, en sık geçen kelime olan "the", tüm kelimelerin yaklaşık %7'sini oluşturmaktadır (1 milyondan biraz fazla kelimenin 69.971'i). Zipf Yasası'na uygun olarak, ikinci sıradaki "of" kelimesi kelimelerin %3,5'inden biraz fazlasını (36.411 kez) oluştururken, onu "and" (28.852) kelimesi takip etmektedir. Büyük bir örneklemdeki kelimelerin yarısını açıklamak için sadece yaklaşık 135 kelimeye ihtiyaç vardır.
Aynı ilişki, çeşitli ülkelerdeki şehirlerin nüfus sıralamaları, şirket büyüklükleri, gelir sıralamaları vb. gibi dille ilgisi olmayan diğer birçok sıralamada da görülür. Nüfusa göre şehir sıralamalarında dağılımın ortaya çıkışı ilk olarak 1913 yılında Felix Auerbach tarafından fark edilmiştir.
Zipf yasasının neden çoğu dil için geçerli olduğu bilinmemektedir.
Görsel galerisi
3 Görseller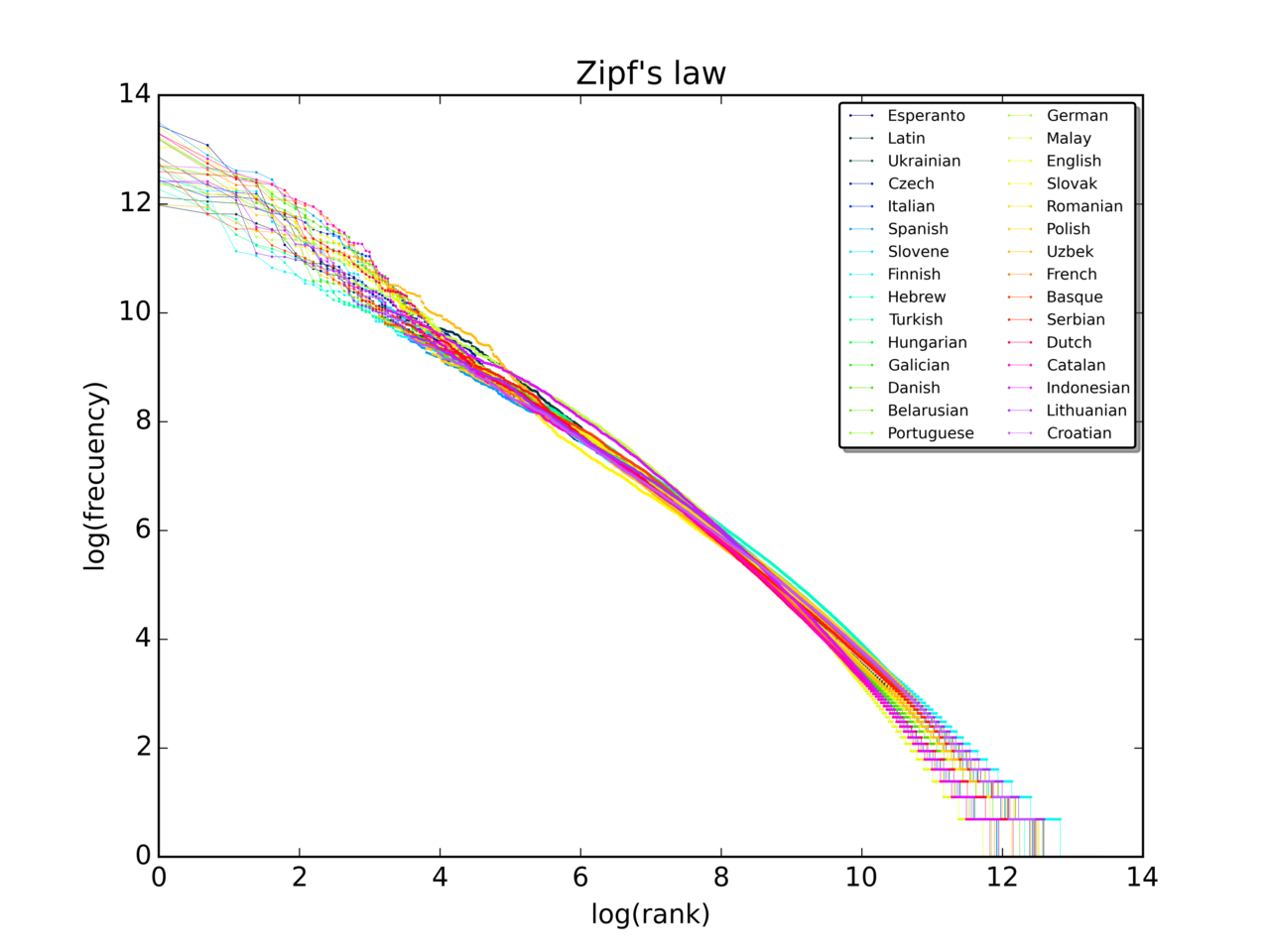


Sorular ve yanıtlar
S: Zipf yasası nedir?
C: Zipf yasası, büyük bir örneklemde bir kelimenin sıklığının, sıklık tablosundaki sırası ile ters orantılı olduğunu belirten deneysel bir yasadır.
S: Zipf yasasını kim önerdi?
C: Zipf yasası ilk olarak bir dilbilimci olan George Kingsley Zipf tarafından önerilmiştir.
S: Zipf yasası İngilizce kelimelerden oluşan bir örneklemdeki kelime sıklığını nasıl açıklar?
C: Zipf yasasına göre, İngilizce kelimelerden oluşan bir örneklemde en sık rastlanan kelime, ikinci en sık rastlanan kelimeden yaklaşık iki kat, üçüncü en sık rastlanan kelimeden üç kat daha sık görülür. Bu eğilim, kelimenin sıralaması azaldıkça devam eder.
S: İngilizce kelimelerden oluşan bir örneklemde en sık rastlanan kelime tüm kelimelerin yüzde kaçını oluşturur?
C: İngilizce kelimelerden oluşan bir örneklemde, en sık geçen kelime ("the") tüm kelimelerin yaklaşık %7'sini oluşturmaktadır.
S: Örneklemin yarısını açıklamak için gereken kelime sayısı ile bu kelimelerin sıklığı arasındaki ilişki nedir?
C: Zipf yasasına göre, büyük bir örneklemdeki kelimelerin yarısını açıklamak için sadece yaklaşık 135 kelimeye ihtiyaç vardır.
S: Başka hangi sıralamalar Zipf yasasını sergiler?
C: Zipf yasasının kelime sıklığında tanımladığı aynı ilişki, çeşitli ülkelerdeki şehirlerin nüfus sıralamaları, şirket büyüklükleri ve gelir sıralamaları gibi dille ilgisi olmayan diğer sıralamalarda da ortaya çıkar.
S: Şehirlerin nüfusa göre sıralanmasında dağılımın ortaya çıktığını kim fark etti?
C: Nüfusa göre şehir sıralamalarında dağılımın ortaya çıkışı ilk olarak 1913 yılında Felix Auerbach tarafından fark edilmiştir.
İlgili makaleler
Yazar
AlegsaOnline.com Zipf yasası Leandro Alegsa
URL: https://tr.alegsaonline.com/art/110649
Kaynaklar
- books.google.com : P. 139